
In questo breve tutorial andremo a vedere come poter estrarre automaticamente i riferimenti ai file JS e CSS presenti in una pagina web.
Prima di iniziare creiamo un nuovo nuovo blocco note su Colab.
Per poter fare questa estrazione in automatico utilizzeremo BeautifulSoup come parser HTML.
from bs4 import BeautifulSoup
Iniziamo inizializzando la sessione HTTP e impostando lo User agent come un normale browser.
import requests
from bs4 import BeautifulSoup as bs
from urllib.parse import urljoin
# URL della pagina web da estrarre
url = "INSERIRE UN URL"
# inizializza una sessione
session = requests.Session()
# imposta l'User-agent come un browser
session.headers["User-Agent"] = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36"
Ora per scaricare tutto il contenuto HTML di quella pagina web, quello che dobbiamo fare è chiamare il metodo session.get(), che restituisce un oggetto response, siamo interessati solo al codice HTML, non all'intera risposta:
# prende il contenuto HTML della pagina
html = session.get(url).content
# fa il parsing HTML della pagina con beautiful soup
soup = bs(html, "html.parser")
Ora abbiamo la nostra risorsa, estraiamo tutti i file script e CSS, usiamo il metodo soup.find_all() che restituisce tutti gli oggetti HTML della risorsa filtrati con i tag e gli attributi passati:
# prende i file Javascript
script_files = []
for script in soup.find_all("script"):
if script.attrs.get("src"):
# se il tag ha l'attributo 'src'
script_url = urljoin(url, script.attrs.get("src"))
script_files.append(script_url)
Quindi, fondamentalmente stiamo cercando i tag script che hanno l'attributo src, questo di solito si collega ai file Javascript necessari per il sito web.
Allo stesso modo, possiamo usarlo per estrarre i file CSS:
# prende i file CSS
css_files = []
for css in soup.find_all("link"):
if css.attrs.get("href"):
# se il tag ha un attributo 'href'
css_url = urljoin(url, css.attrs.get("href"))
css_files.append(css_url)
Come forse sapete, i file CSS sono all'interno degli attributi href nei tag di collegamento. Stiamo usando la funzione urljoin() per assicurarci che il link sia assoluto (cioè con percorso completo, non un percorso relativo come /js/script.js).
Infine, stampiamo il totale dei file script e CSS e scriviamo i link in file separati:
print("Script JS totali in pagina:", len(script_files))
print("Totale file CSS in pagina:", len(css_files))
# write file links into files
with open("javascript_files.txt", "w") as f:
for js_file in script_files:
print(js_file, file=f)
with open("css_files.txt", "w") as f:
for css_file in css_files:
print(css_file, file=f)
Una volta eseguito il codice, appariranno 2 file all'interno della vostra cartella in Colab, uno per i collegamenti Javascript e l'altro per i file CSS:
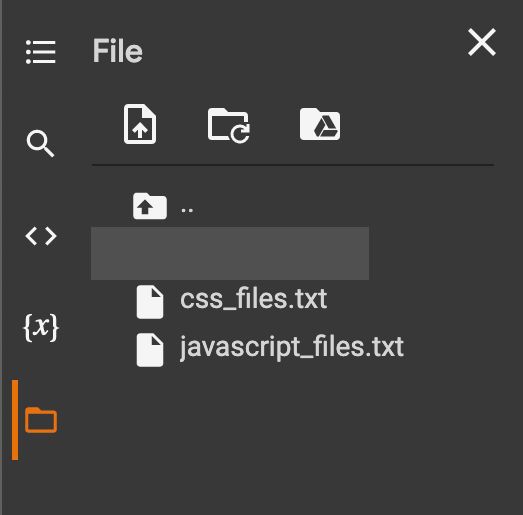
- css_files.txt
- javascript_files.txt





{kind=link}